
A Brief Introduction to Continual Learning
Learning continually without forgetting

Modern AI models are remarkably capable but, in an important sense, they are largely static. A frontier large language model (LLM) is trained once, frozen, and shipped. Its knowledge of the world is fixed at the moment its training data was collected, and from then on it is, in effect, a brilliant amnesiac — extraordinarily able, but unable to learn anything new from its own experience.
Biological intelligence is not like this. Humans and other animals continually integrate new experiences into existing knowledge, refine old skills, and acquire new ones, all while preserving the competencies they already had. The aspiration to give artificial systems this same capability is the central question of continual learning.
In this post I provide a brief introduction to continual learning (CL): what it is, why it is hard, the canonical approaches that have been developed, and why the topic has resurged with such force in the era of foundation models. The aim is to provide an accessible entry point for those new to the area, while pointing to some of the key papers along the way for those wanting to dig deeper. For a much more comprehensive treatment, see the recent surveys [1,2,3] and the excellent post on Shawn Wang’s Blog.

What is continual learning?
Continual learning — also called lifelong or incremental learning — is the ability of a model to incrementally acquire, update, and exploit knowledge from a non-stationary stream of data over time, ideally without losing prior competencies and while transferring across experiences (see the comprehensive survey by Wang and colleagues [3]).
Two ingredients distinguish CL from related notions:
1. The data distribution changes over time — we receive a stream of tasks, domains, or simply newer data, rather than a single fixed dataset.
2. We typically cannot freely access past data — either because of memory, privacy, or compute constraints.
Several neighbouring concepts are easily confused with CL but answer different questions. Transfer learning reuses knowledge from a source for a target task, but performance on the source is not a concern; CL requires retention across all past tasks. Multi-task learning trains on all tasks jointly with simultaneous data access — it is the standard "joint training" upper bound, but not CL. Online learning concerns a stream of (often i.i.d.) samples for a single stationary task. CL adds non-stationarity and the explicit requirement to retain past knowledge.
There is also a related but distinct line of work called open-ended learning, which asks how a system can keep generating novel, increasingly interesting challenges and capabilities indefinitely. Where CL is largely reactive — adapting to a stream the world hands it — open-ended learning is generative, with the system inventing its own curriculum. The two are increasingly entangled in the modern setting (a self-play agent that generates its own tasks needs CL machinery to retain what it discovers), but it is worth keeping them conceptually separate.
Catastrophic forgetting and the stability–plasticity dilemma
The reason CL is hard has a name: catastrophic forgetting (see Figure 1). When a neural network is trained on a new task using standard gradient descent, it tends to overwrite the weights that encoded knowledge of previous tasks. Performance on prior tasks then collapses, often dramatically.
This phenomenon was first identified and named by McCloskey and Cohen in 1989 [4], revisited by French in 1999 [5], and demonstrated for modern deep networks by Goodfellow et al. [6]. The intuition is straightforward: distributed gradient-based representations encode tasks via overlapping weights, and stochastic gradient descent on a new task pushes those weights wherever reduces the new loss, with no pressure to preserve old-task loss.
Catastrophic forgetting is one side of a more general trade-off, known since Grossberg's work in the 1980s as the stability–plasticity dilemma [7]: a system must be plastic enough to acquire new information, yet stable enough to retain old information. Too much plasticity and you forget; too much stability and you cannot learn. CL is, fundamentally, the search for a principled way to navigate this trade-off.
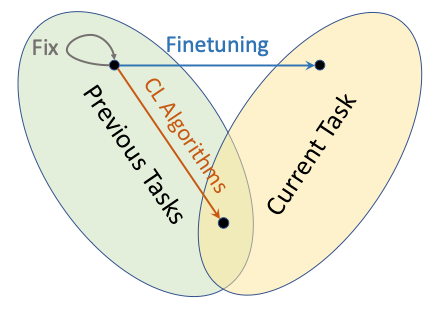
Figure 1: The stability–plasticity trade-off. Freezing the model (Fix) preserves prior knowledge but acquires nothing new. Standard fine-tuning adapts to the current task but drifts out of the region that solved previous tasks (catastrophic forgetting). Continual learning (CL) algorithms aim for the intersection — solutions that perform well on both previous and current tasks. (Credit: Shawn Wang’s blog post.)
Three families of classical methods
Faced with catastrophic forgetting, the CL community has converged, broadly, on three families of methods (a useful taxonomy is given by De Lange et al. [8]).
Regularisation-based methods add a penalty term that discourages weight changes which would damage performance on previous tasks. The canonical example is Elastic Weight Consolidation (EWC) [9], which uses a Fisher-information-weighted quadratic penalty around the weights important for past tasks. The idea is elegant and biologically inspired: identify which synapses matter, and slow learning down on those synapses while letting others adapt freely. Synaptic Intelligence and Memory Aware Synapses are conceptually similar variants.
Replay-based methods mix a small amount of past data — either real samples held in a buffer, or synthetic samples produced by a generative model — into the training of new tasks. Experience replay with reservoir sampling is a surprisingly strong baseline, and Deep Generative Replay [10], inspired by the Complementary Learning Systems framework from cognitive neuroscience, replaces stored data with samples from a learned generator. Replay turns out to be remarkably hard to beat: a famously simple buffer-based method called GDumb [11] embarrassed many sophisticated methods on standard benchmarks, and the field had to take stock.
Architectural methods dedicate different parameters to different tasks. Progressive Networks [12] grow a new column of the network for each task with lateral connections to previous columns — eliminating forgetting at the cost of linear parameter growth. PackNet iteratively prunes and freezes weights so that each task occupies a different subnet of a fixed-size model. These approaches buy you stability through structural separation rather than careful optimisation.
Each family has strengths and weaknesses. On one hand regularisation is parameter-efficient but tends to fail in the harder settings, where new classes arrive sequentially and the model must classify across all of them without being told which task is active; on the other hand replay works well but raises memory and privacy concerns; while architectural methods give strong guarantees but scale poorly in their basic form. The empirical consensus that has emerged is that replay is essentially required in these harder settings at modest scale, and that strong pretrained backbones change the picture substantially — sometimes a frozen backbone with a class-mean classifier rivals elaborate methods.
Continual learning in the era of foundation models
Until a few years ago, CL was largely a self-contained subfield with its own benchmarks (Permuted MNIST, Split CIFAR, CORe50) and a relatively stable set of methods. The arrival of foundation models has changed the landscape almost entirely.
Three things are different in the foundation-model regime.
First, the base model is enormously expressive and broadly competent before any task-specific training begins. This blunts catastrophic forgetting in some respects (the pretrained representations are robust) while sharpening it in others (a small fine-tune can quietly degrade capabilities the user never thought to test).
Second, full retraining is no longer an option for most practitioners — frontier models are expensive to train. CL is therefore not just intellectually attractive but operationally necessary, and "how do I keep my model up to date?" has become a first-order question.
Third, the knobs available to us are different. We have parameter-efficient adaptation, in-context learning, retrieval augmentation, model editing, and model merging, in addition to the classical CL toolkit. Each is, in its own way, a partial answer to the CL question.
For LLMs specifically, CL is naturally organised around the three stages of the modern training pipeline — continual pre-training, continual fine-tuning, and continual alignment [1, 2] — with different methods favoured at each.
A pragmatic recipe for continual pretraining of LLMs has settled into something close to a gold standard: learning-rate re-warming, learning-rate re-decaying, and replaying a small fraction of the previous data. Ibrahim and colleagues [13] demonstrate that this combination matches full retraining on the union of old and new data, validated up to 10B parameters. Recent work on time-continual benchmarks at web scale, such as Apple's TiC-LM (114 Common Crawl dumps spanning years of the web), confirms that with the right schedule the compute cost can be reduced by roughly 2–3× compared to retraining from scratch, while matching loss.
Beyond continued pretraining, several other directions are particularly active:
Parameter-efficient adaptation as CL. A large family of methods uses Low Rank Adaptation (LoRA) adapters, often arranged in orthogonal subspaces or as mixtures of experts, to absorb new tasks without disturbing the base weights. The appeal is obvious — a small, isolated set of parameters per task is the modern descendant of the architectural family above.
Knowledge editing. Methods such as ROME, MEMIT, and the recent AlphaEdit [14] surgically modify specific facts inside a model's weights without retraining. The latest generation, based on null-space projection of perturbations onto preserved-knowledge directions, has dramatically improved sequential edit robustness — though ripple effects (an edit that fails to propagate to entailed facts) and degradation on multi-hop reasoning remain hard problems.
Model merging and task arithmetic. A surprisingly fruitful line of work treats the difference between a fine-tuned model and its base as a task vector that can be added, subtracted, or combined [15]. Methods like TIES-Merging and DARE refine this idea, and merging has become a practical way to combine specialised models without retraining.
Memory and retrieval. Retrieval-augmented generation externalises knowledge updates entirely: rather than putting new information in the weights, we put it in a retrievable store. This is the most-deployed form of "continual learning" today, even if it is a slightly different beast — knowledge lives outside the weights and is retrieved on demand.
Test-time adaptation. A fast-growing 2024–2026 frontier blurs the line between inference and learning. Methods such as Test-Time Training [16] update a small set of parameters with each incoming input, treating the forward pass itself as a self-supervised learning step.
A recent and influential conceptual shift comes from Shenfeld, Pari and Agrawal [17], who show that on-policy reinforcement learning forgets less than supervised fine-tuning, and that forgetting is well-predicted by the KL divergence between the fine-tuned and base policies on the new task. This reframes CL, in part, as a problem of distributional control — a perspective that connects naturally to alignment, since the same lens helps explain why fine-tuning can compromise safety properties even on benign data.
Is continual learning the bottleneck to AGI?
A debate that has spilled out of the research community and into broader AI commentary is whether continual learning is the bottleneck on the path to artificial general intelligence. Some commentators (notably Dwarkesh Patel, with sympathetic noises from Ilya Sutskever, Demis Hassabis, and others) argue that today's models cannot learn from on-the-job experience the way humans do, and that no amount of scale will fix this without a paradigm shift. Others (Nathan Lambert, arguably Andrej Karpathy) argue that CL is largely a systems problem: better context handling, longer reinforcement learning, more frequent intermediate checkpoints, and richer memory layers will produce something indistinguishable from CL without a fundamentally new learning algorithm.
A useful sociological observation is that no one yet ships true online weight updates from user data at scale. What is actually deployed is a spectrum: post-training cycles every few weeks, mid-training stages, retrieval, memory layers, LoRA adapters, and federated personalisation. Frontier model release cadences — annual base retrains punctuated by rapid post-training iterations — are starting to look more like software updates than learning episodes, but this is release cadence, not continual learning.
Whether the gap between this and "true" CL is fundamental or merely engineering is, perhaps, the most important open question in the field.
Future perspectives
Continual learning is one of those topics that looks deceptively simple from the outside — surely we just want models that keep learning? — and turns out to be deeply hard once one starts to specify what that actually means.
What is most striking about the current moment is that CL is being approached from many directions at once. Classical CL theory continues to develop (with NTK-based, mode-connectivity, and statistical-physics analyses all making progress). Foundation-model practitioners are converging on hybrid recipes — continued pretraining with replay, LoRA-based modular adaptation, knowledge editing, merging, retrieval, and increasingly test-time adaptation. New architectural proposals such as Google's Nested Learning [18] and MIT's Self-Adapting Language Models (SEAL) [19] are explicitly designed around continual updates, with self-modifying components that operate at multiple timescales. Reinforcement-learning-based post-training is beginning to look, suggestively, like CL by another name.
Whether all of this converges on a clean, satisfying answer — Sholto Douglas of Anthropic has publicly predicted CL will be "solved in a satisfying way" in 2026, which one can read as either bold or cautious — is impossible to know yet. What is clear is that the question of how AI systems can learn continually, robustly, safely, and efficiently is one of the central problems of the next phase of the field.
References
[1] Shi et al., Continual Learning of Large Language Models: A Comprehensive Survey, ACM Computing Surveys (2025), arXiv:2404.16789
[2] Chen, Sun, Ye, Li & Lin, Continual Learning in Large Language Models: Methods, Challenges, and Opportunities (2026), arXiv:2603.12658
[3] Wang, Zhang, Su & Zhu, A Comprehensive Survey of Continual Learning, IEEE TPAMI (2024), arXiv:2302.00487
[4] McCloskey & Cohen, Catastrophic Interference in Connectionist Networks: The Sequential Learning Problem, Psychology of Learning and Motivation, Vol. 24 (1989), DOI
[5] French, Catastrophic forgetting in connectionist networks, Trends in Cognitive Sciences (1999), DOI
[6] Goodfellow, Mirza, Xiao, Courville & Bengio, An Empirical Investigation of Catastrophic Forgetting in Gradient-Based Neural Networks (2013), arXiv:1312.6211
[7] Grossberg, Competitive Learning: From Interactive Activation to Adaptive Resonance, Cognitive Science (1987), DOI
[8] De Lange et al., A Continual Learning Survey: Defying Forgetting in Classification Tasks, IEEE TPAMI (2021), arXiv:1909.08383
[9] Kirkpatrick et al., Overcoming catastrophic forgetting in neural networks, PNAS (2017), arXiv:1612.00796
[10] Shin, Lee, Kim & Kim, Continual Learning with Deep Generative Replay, NeurIPS (2017), arXiv:1705.08690
[11] Prabhu, Torr & Dokania, GDumb: A Simple Approach that Questions Our Progress in Continual Learning, ECCV (2020), DOI
[12] Rusu et al., Progressive Neural Networks (2016), arXiv:1606.04671
[13] Ibrahim et al., Simple and Scalable Strategies to Continually Pre-train Large Language Models, TMLR (2024), arXiv:2403.08763
[14] Fang et al., AlphaEdit: Null-Space Constrained Knowledge Editing for Language Models, ICLR Outstanding Paper (2025), arXiv:2410.02355
[15] Ilharco et al., Editing Models with Task Arithmetic, ICLR (2023), arXiv:2212.04089
[16] Sun et al., Learning to (Learn at Test Time): RNNs with Expressive Hidden States (2024), arXiv:2407.04620
[17] Shenfeld, Pari & Agrawal, RL's Razor: Why Online Reinforcement Learning Forgets Less (2025), arXiv:2509.04259
[18] Behrouz, Razaviyayn, Zhong & Mirrokni, Nested Learning: The Illusion of Deep Learning Architectures, NeurIPS (2025), arXiv:2512.24695
[19] Zweiger, Pari, Guo, Akyürek, Kim & Agrawal, Self-Adapting Language Models, MIT (2025), arXiv:2506.10943
Ideas my own. Writing a collaborative effort with AI.